ChatGPT's hidden result_source:how it really sources hotel answers
TL;DR: Every web page ChatGPT retrieves carries an undocumented tag, result_source, naming the pipeline that fetched it. Across 30,002 hotel citations, 99.85% come from one licensed tier (labrador) and the open-web serp tier never appears. A companion field decides whether the web is searched at all — and 37.3% of hotel questions never search. Within the licensed tier, ChatGPT cites official brand sites 77–86% of the time while discarding the aggregator listicles it retrieves.
Executive Summary
ChatGPT runs hotel search on a licensed retrieval tier — and tells you so in a field users never see.
ChatGPT's web-search stream stamps every retrieved page with result_source — the pipeline or vendor that fetched it — and classifies each query with turn_use_case before it decides to search. Neither is documented. We backfilled both across our full ChatGPT hotel capture history: 50,899 captures and 30,002 tier-tagged citations.
The picture is lopsided and actionable. Hotels are sourced almost entirely from the licensed labrador tier (99.85%); the open-web serp baseline never appears. The field is brand new (first seen 26 May 2026) and was rolled out intermittently. And inside the licensed tier, retrieved is not cited: official brand sites win, aggregator listicles get pulled and dropped.
A three-tier sourcing system, hidden in plain sight
Every search_result block in ChatGPT's raw response carries a result_source tag next to the publisher attribution and publish date. It takes one of a small set of values — and for hotels, one of them dominates completely.
| result_source | Share of tagged citations | What it is |
|---|---|---|
| labrador | 99.85% | Licensed / quality-gated content tier |
| bright | 0.14% | Bright Data structured web datasets |
| oxylabs | 0.01% | Scraped open web (Oxylabs is a scraping vendor) |
| serp | 0% | Open-web baseline — never appears for hotels |
What it looks like in the raw stream
// labrador — licensed editorial / OTA / brand content
{ ..., "pub_date":1777852800,
"result_source":"labrador",
"attribution":"discoverzermatt.com" }
// bright — Bright Data structured dataset (an individual luxury hotel)
{ ..., "result_source":"bright",
"attribution":"Schweizerhof Zermatt" }
// oxylabs — scraped open web
{ ..., "result_source":"oxylabs",
"attribution":"Tripadvisor" }labrador, 99.85%). The open-web serp tier that appears in other verticals never shows up — the model isn't reading the live SERP for hotels, it's reading a curated feed.A brand-new field — switched on, off, then on again
Because we have citations from before the field existed, the share carrying a tag traces the rollout. It first appears on 26 May 2026, peaks the first week of June, then drops sharply — the signature of a staged experiment, not a permanent flip.
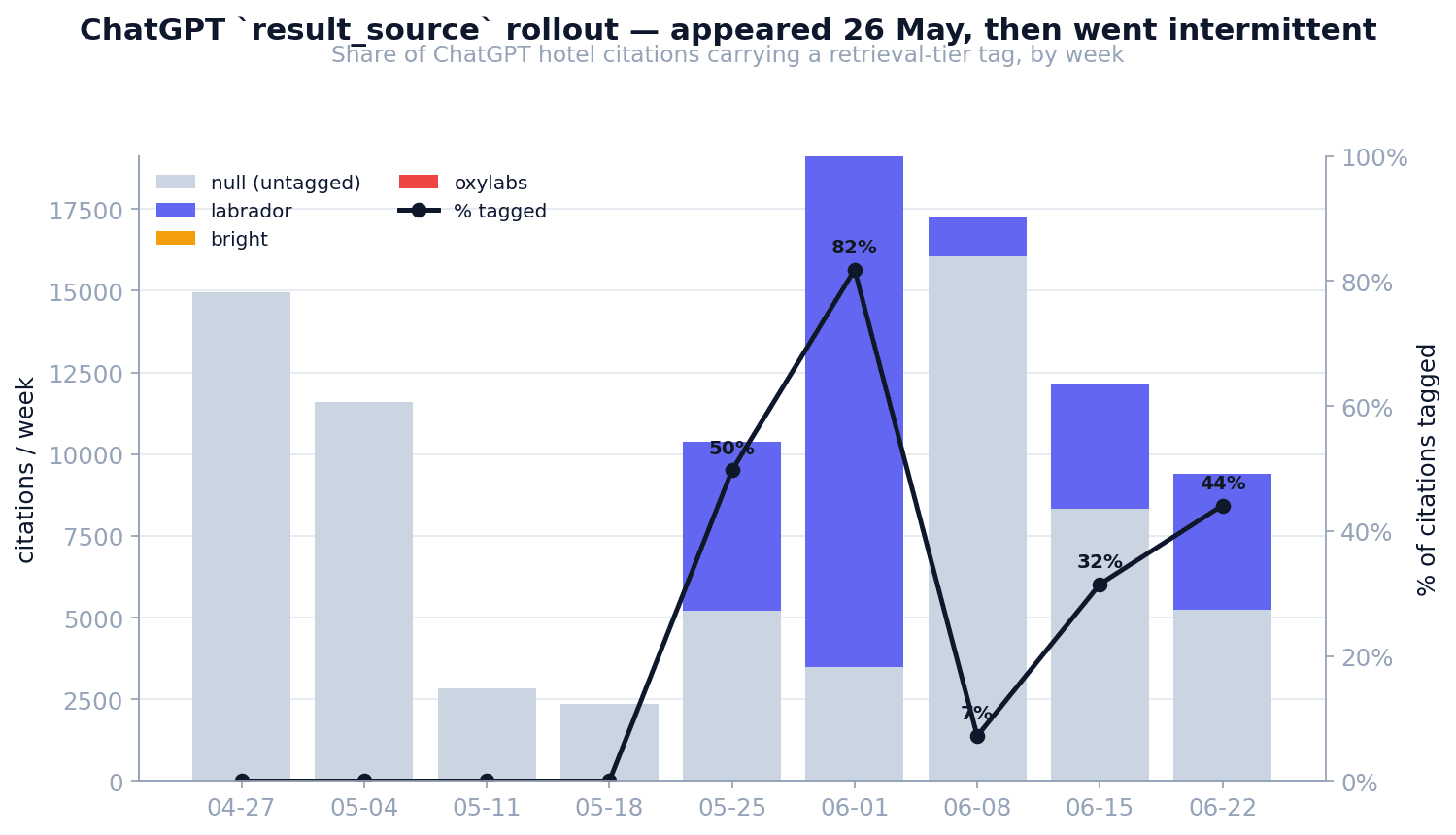
Does your question even reach the web?
Before any retrieval, turn_use_case files the query into a bucket that decides which pipelines fire. For hotels, the single most common bucket is text — which means no web search at all.
| turn_use_case | Share of turns | Hits the web? |
|---|---|---|
| text | 37.3% | No — answered from training data |
| search | 31.8% | Yes |
| local | 26.3% | Yes (maps / places) |
| instant search | 3.3% | Yes |
| instant answers | 1.3% | Partial |
| thinking / unknown | 0.1% | — |
Retrieved ≠ cited: who ChatGPT actually trusts
These are the top domains ChatGPT retrieves inside the labrador tier, with the share of those retrievals it actually cites. The gap is the whole story.
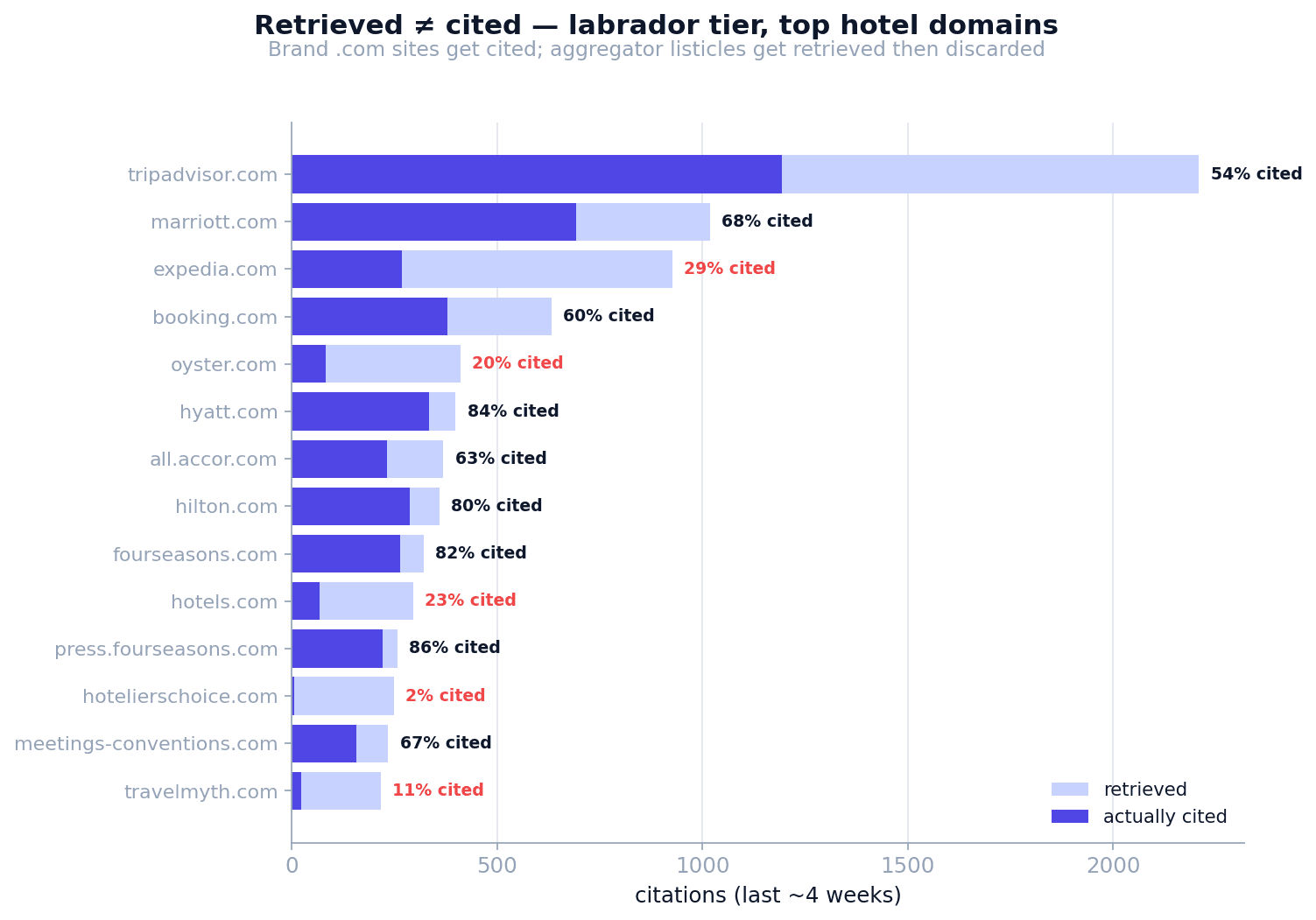
| Domain | Retrieved | Cited % | Type |
|---|---|---|---|
| tripadvisor.com | 2,209 | 54% | Review aggregator |
| marriott.com | 1,019 | 68% | Brand |
| expedia.com | 926 | 29% | OTA |
| booking.com | 632 | 60% | OTA |
| oyster.com | 411 | 20% | Aggregator |
| hyatt.com | 399 | 84% | Brand |
| hilton.com | 360 | 80% | Brand |
| fourseasons.com | 321 | 82% | Brand |
.com sites are cited 77–86% of the time when retrieved; aggregator listicles 1–11%. ChatGPT pulls the listicles, then leans on the official source. For hotels, a clean first-party page beats a placement on a “best hotels” roundup.Each tier has a different publisher fingerprint
The three tiers aren't redundant — they map to how a page was acquired, and it shows in what each one carries.
| Tier | Character | Representative sources |
|---|---|---|
| labrador | Licensed / quality-gated — OTAs, big-brand chains, established editorial | tripadvisor.com, marriott.com, booking.com, expedia.com, hyatt.com, hilton.com, fourseasons.com, timeout.com |
| bright | Bright Data structured datasets — premium directories + individual luxury properties | Five Star Alliance, Tablet Hotels, Forbes Travel Guide, montcervinpalace.ch, tajhotels.com, agoda.com |
| oxylabs | Scraped open web — long tail incl. social + individual hotel sites | instagram.com, resortpass.com, thebarnett.com |
bright / oxylabs), not the licensed labrador feed. Big brands and OTAs are licensed in; everyone else is crawled ad-hoc.Study Design
Data Collection
- 50,899 ChatGPT hotel captures via Bright Data, 25 Dec 2025 – 22 Jun 2026.
result_sourceandturn_use_caseparsed out of the raw SSE response stream and joined to 30,002 flattened per-citation rows.- ChatGPT-only — no equivalent field is emitted by Gemini, Perplexity, Copilot or Google AI Mode.
Caveats
- One vertical (hotels) and one collection method; tier mix is query-type dependent.
serpnever appears for hotels (0 of 30,002) but may surface in other verticals.- The field is ~4 weeks old and intermittent;
bright(n=42) andoxylabs(n=3) samples are tiny — directional, not definitive. - Cited % is share-of-retrievals-cited, not a ranking guarantee.
Open data. Headline stats and the underlying tables are published as CSV: summary.csv, weekly_rollout.csv, labrador_top_sources.csv, turn_use_case.csv.