AI Search for Yoga Studios in Berlin (2026):We ran the Paris study again — and the engines behaved identically
TL;DR: Same playbook, different city: 27 prompts, 5 AI engines, EN + DE, matched against 631 real Berlin studios. The three citation personalities we identified in Paris replicate almost to the percentage point — Copilot 95% studio sites (Paris: 96%), ChatGPT 32% studios + 19% Reddit (Paris: 32% + 16%), Google AI Mode 59% cites of google.com (Paris: 52%). The personalities are structural traits of the engines, not city quirks. The Berlin twist: booking platforms now drive up to 31% of citations — blog.urbansportsclub.com (213 cites) and classpass.com (208) are the two most-cited domains in the whole study, ahead of every single studio website.
Executive Summary
The Paris study was a first take. Berlin is the experiment that tells us how much of it was a law of AI search and how much was an artifact of one city.
The setup is a deliberate carbon copy: 27 prompt templates, 5 AI engines (ChatGPT, Perplexity, Gemini, Copilot, Google AI Mode), English and German, both a US and a DE proxy, all in one week. We ran 540 captures, collected 5,293 cited URLs, pulled out the studios each answer named with a named-entity-recognition pass, and matched them to 631 verified Berlin studios.
The headline survives the move from Paris to Berlin almost untouched. Copilot is still a near-pure entity lookup (95% studio websites; Paris: 96%). ChatGPT’s studio-website share is identical to the percentage point (32% in both cities), and Reddit is again its top social source (19% of its URLs; Paris: 16%). Google AI Mode cites google.com back to itself 59% of the time (Paris: 52%). Three engines, three distinct ways of sourcing “best yoga studios” — and the ratios barely move when you change the city. That is strong evidence the personalities are structural traits of the engines, not artifacts of Paris.
The twist is what makes Berlin its own story: booking platforms. In Paris, ClassPass was a meaningful but minor bucket. In Berlin, Urban Sports Club, Eversports and ClassPass collectively dominate the marketplace layer — 31% of Perplexity citations, 27% of Gemini’s, 16% of ChatGPT’s. The single most-cited domain in the entire study is blog.urbansportsclub.com (213 cites), then classpass.com (208) — ahead of every single yoga studio’s own website. Berlin’s fitness-subscription ecosystem (Urban Sports Club and Eversports are German/Austrian-born) has become the primary AI source for “where do I do yoga.” The lesson: AI source mix bends to the local commercial infrastructure, even when the engine personalities don’t.
Paris vs Berlin: the engines barely move
Before anything else, the comparison that makes everything else interesting. Same methodology, same 27 prompts, same 5 engines — different city, different language. If the engine personalities are real traits of the engines, the numbers should hold. They do.
| Platform | Personality | Paris signal | Berlin signal | Verdict |
|---|---|---|---|---|
| Copilot | Entity engine | 96% studio sites | 95% studio sites | Near-identical |
| ChatGPT | Social engine | 32% studios + 16% Reddit | 32% studios + 19% Reddit | Near-identical |
| Google AI Mode | Self-referential | 52% google.com | 59% google.com | Replicates |
| Perplexity | Mixed-source | 52% studios + ~9% booking | 45% studios + 31% booking | Booking surge |
| Gemini | Mixed-source | 41% studios + editorial | 55% studios + 27% booking | Booking surge |
Three source strategies, replicated
For every cited URL we bucketed the source: the studio’s own website, a booking platform, a social post, an editorial outlet, a wellness blog, a Google SERP, or other. The result is the same three-camp split we saw in Paris — just with one bucket (booking) inflated by Berlin’s commercial mix.
Entity engine
Copilot. Cites the studio’s own website directly. 95% pure studio-domain citations — basically an entity-resolution lookup. Paris counterpart: 96%. Almost no booking-platform citations at all.
Social / editorial engine
ChatGPT. 19% Reddit, 9% editorial, 9% wellness blogs — only 32% studio websites. Paris counterpart: 32% studios, 16% Reddit. ChatGPT learns about Berlin yoga from communities and journalists, with Reddit again its single #1 source.
Self-referential engine
Google AI Mode. 59% google.com URLs — Google citing its own SERP back. Real source diversity is low; the answer is essentially a re-presented search results page. Paris counterpart: 52%.
The Berlin booking surge. Booking platforms — Urban Sports Club, Eversports and ClassPass — drive up to 31% of Perplexity citations, 27% of Gemini, and 16% of ChatGPT. In Paris, the equivalent layer was 9% on Perplexity at its peak. This is the one place where the city, not the engine, sets the dial.
The Berlin yoga studio AI leaderboard
Aggregating mentions across all five engines (chain locations merged), these are the most-cited Berlin yoga studios. “Plats” is the number of the 5 engines that surfaced the studio at all — a breadth signal. Berlin’s top tier is highly consistent: 8 of the top 12 are surfaced by all five engines, in contrast with Paris where Modo Yoga’s #4 finish was undermined by zero citations on Gemini and AI Mode.
The studios AI recommends most for Berlin — scored across ChatGPT, Perplexity, Gemini, Copilot and Google AI Mode combined.
| Rank | Studio | Score | Plats |
|---|---|---|---|
| #1 | Yogicescape – Yoga & Wellness Studio | 213 | 5 / 5 |
| #2 | Jivamukti Yoga School | 151 | 5 / 5 |
| #3 | YOU GLOW Yoga & Womanhood Mitte | 143 | 4 / 5 |
| #4 | SHA-LA Studios Prenzlauer Berg | 125 | 5 / 5 |
| #5 | YCBA YogaCircle Berlin Akademie | 121 | 4 / 5 |
| #6 | YOGA REBELLION – Berlin Mitte | 106 | 4 / 5 |
No Modo-style blindspot here. Unlike Paris — where Modo Yoga ranked #4 overall yet scored zero on Gemini and Google AI Mode — Berlin’s top tier wins across all five engines. The all-5 sweep includes Yogicescape, Jivamukti, SHA-LA, Ashtanga Yoga Berlin, yogafürdich, VIVA, Three Boons, Ashtanga Studio, plus the next tier down (SUN YOGA Kreuzberg, Dharma Yoga, yogibar, Lotos Yoga Loft, Mysore Shala, Yoga On The Move, YOGA SKY).
The top cited sources
Buckets are one thing; the actual domains are another. Here are the most-cited domains across all engines — and the giveaway: three of the top six are booking platforms. In Paris, studio domains and ClassPass/Vogue led; in Berlin, Urban Sports Club’s blog and ClassPass sit at the very top, ahead of every yoga studio.
| Plats | Cites | Bucket | Domain |
|---|---|---|---|
| 5 / 5 | 213 | booking | blog.urbansportsclub.com |
| 5 / 5 | 208 | booking | classpass.com |
| 5 / 5 | 195 | studio | yogicescape.de |
| 5 / 5 | 102 | studio | shalastudios.com |
| 5 / 5 | 98 | booking | urbansportsclub.com |
| 5 / 5 | 77 | studio | yfdberlin.com |
The top sources, model by model
The five most-cited sources for each engine, as a share of all the URLs it cited. The signature source for each is highlighted in the first row — and they could hardly be more different.
ChatGPT
433 cited URLsreddit.com18.7%blog.urbansportsclub.com4.8%classpass.com4.2%top10berlin.de3.5%yogicescape.de3%Reddit again the #1 social source — 19% of its URLs. Studio share is 32%, identical to Paris.
Perplexity
1,262 cited URLsblog.urbansportsclub.com8.3%classpass.com7.1%yogicescape.de4.1%eversports.de2.5%shalastudios.com2.4%Highest volume — and the most booking-dependent engine in Berlin. 31% of its URLs are booking platforms.
Gemini
298 cited URLsblog.urbansportsclub.com12.1%classpass.com11.7%yogicescape.de6.4%eversports.de4.7%top10berlin.de2.7%Few sources, highly concentrated — and 27% booking. Urban Sports Club punches above its weight.
Copilot
741 cited URLsyogicescape.de9%shalastudios.com6.5%yfdberlin.com5.4%threeboonsyoga.de4.6%ashtangastudio.de4%Top to bottom, studio websites — 95% entity lookup. Bypasses booking platforms almost entirely.
Google AI Mode
2,559 cited URLsgoogle.com59%blog.urbansportsclub.com2.4%classpass.com1.6%yogicescape.de1.5%reddit.com1.4%59% of its URLs are google.com — it cites its own search results back to itself.
The booking layer: Urban Sports Club, Eversports, ClassPass
Paris had a marketplace layer (ClassPass) but it was a minor force. Berlin is different. The city has a deeper fitness-subscription ecosystem — Urban Sports Club (Berlin-born, Europe-wide) and Eversports (Vienna-born, very strong in DACH) on top of ClassPass — and AI engines have folded all three into their grounding sources. The result is a marketplace layer that, on some engines, rivals the studios themselves.
blog.urbansportsclub.com — the single most-cited domain in the study, ahead of every studio.classpass.com — #2 overall. Paris’s top OTA holds its weight here too.urbansportsclub.com — the marketplace landing pages on top of the blog.eversports.de — the German booking platform that did not register in Paris.Paris (ClassPass alone) vs Berlin (the booking trio)
- ClassPass is the single most-cited domain (146), but the marketplace bucket is ~9% on Perplexity at peak.
- Gymlib barely registers (14 cites, ChatGPT only).
- Booking engines (Mindbody, bsport) are negligible.
blog.urbansportsclub.com(213) andclasspass.com(208) are #1 and #2 overall.- The marketplace bucket is 31% on Perplexity, 27% on Gemini, 16% on ChatGPT.
- Eversports (73 cites) is a real third marketplace, not a rounding error.
The lesson: AI engine personalities are stable, but the source mix bends to the local commercial infrastructure. Berlin has a denser subscription/booking ecosystem than Paris, and AI reflects it. Any city with strong vertical marketplaces (Urban Sports Club in DE, MoveGB in UK, ClassPass globally) will skew booking-heavy.
Language and TLD bias: stronger than Paris
The Paris finding — that asking the same question in two languages returns mostly different studios — replicates exactly. Berlin adds one wrinkle: the local-TLD bias is stronger here. German domains do not just survive on German prompts the way .frdid; they are actively favoured.
EN vs DE overlap by template (ChatGPT, DE proxy)
| Template | EN vs DE top-5 overlap (Jaccard) |
|---|---|
| style_ashtanga | 100% — proper-noun anchor |
| style_mysore | 100% |
| dist_mitte / dist_prenzlberg / dist_charlottenburg | 67% |
| style_hot | 67% |
| prenatal / dist_kreuzberg | 43% |
| style_restorative / style_vinyasa | 43% |
Identical pattern to Paris. Proper-noun queries (Ashtanga, Mysore) converge 100% across languages — there is one right answer. Generic-intent queries (affordable, teacher training, morning, community) diverge completely — EN and DE prompts return entirely different studios. Language reshapes the answer set whenever the query is not anchored to a named style.
TLD bias: .de and .berlin are German-biased
| TLD | Studios | EN cites | DE cites | DE/EN ratio | Reading |
|---|---|---|---|---|---|
| .de | 22 | 30 | 45 | 1.50× | local-biased |
| .com | 8 | 20 | 14 | 0.70× | EN-biased |
| .berlin | 3 | 1 | 5 | 5.00× | strongly local-biased |
| .yoga | 2 | 2 | 3 | 1.50× | local-biased |
Berlin shows a stronger local-TLD bias than Paris. In Paris, .fr was language-neutral (1.0×) and only .com skewed English. In Berlin, .de is actively German-biased (1.5×) and .berlin overwhelmingly so (5×). German prompts pull German-TLD studios harder than French prompts pulled French ones.
.de or.berlin domain is not just a vanity choice — it earns disproportionate visibility on German-language AI queries, which is exactly the audience most likely to be searching from Berlin. A .com leaks German-language citations.One tilt runs the other way, though, and it’s easy to miss behind the strong .de bias: the corpus these models train on, and the retrievers that rank sources, both skew heavily toward English. So while German prompts pull German-TLD studios hard, the English answer set for Berlin draws on a much larger English-language library — and a studio with no English presence simply isn’t in it. The .de domain wins you the local German audience; a genuinely useful English edition is what wins you the anglophone-expat-and-tourist half of Berlin that searches in English.
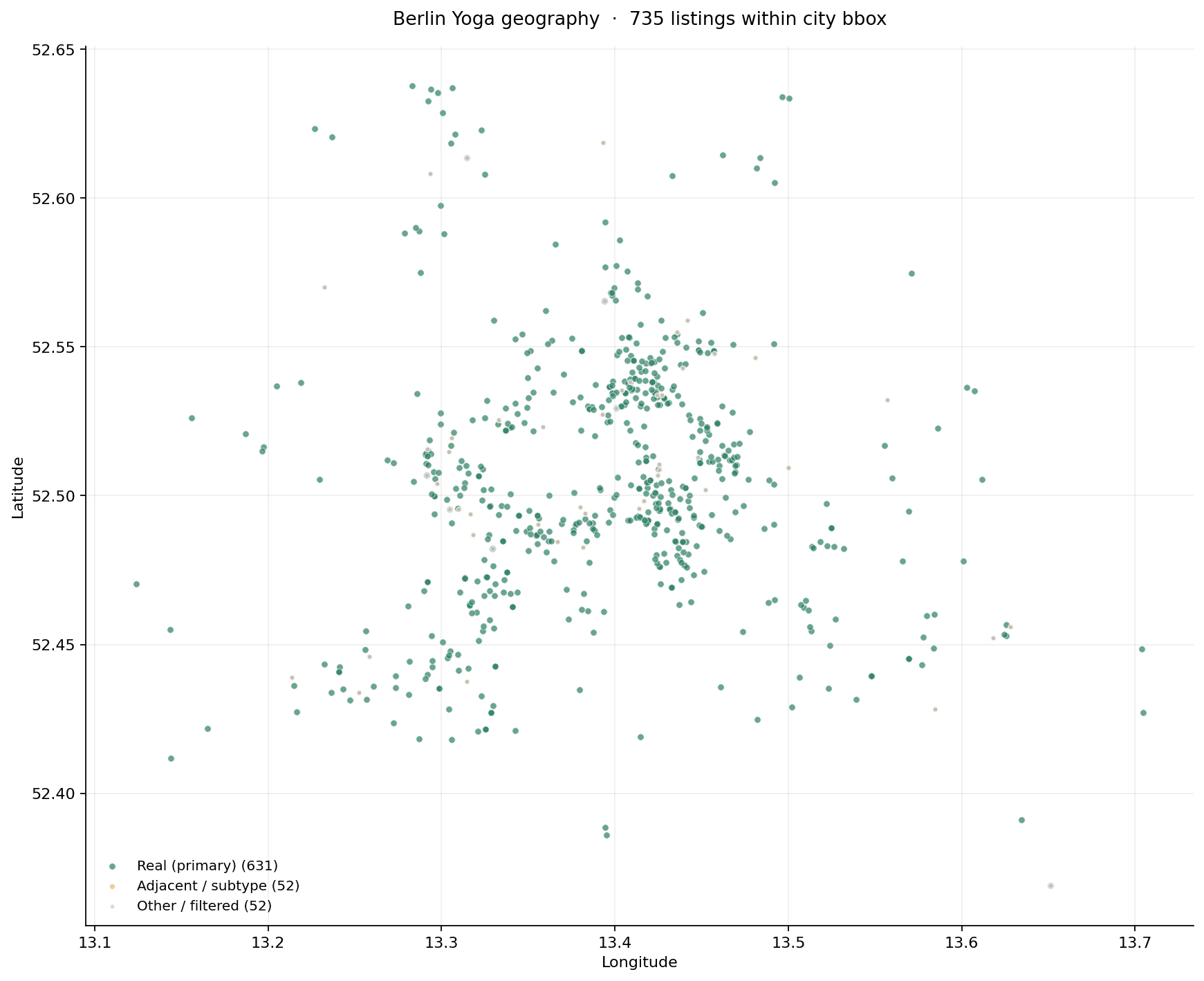
Geography: 631 studios on the map
The reference set the answers were resolved against. Density follows the eastern Bezirke — Mitte, Prenzlauer Berg, Friedrichshain, Kreuzberg — with thinner coverage in the outer western suburbs.
District-accuracy caveat — null test, not a finding
For Berlin’s six Bezirke (Mitte, Prenzlauer Berg, Kreuzberg, Friedrichshain, Neukölln, Charlottenburg) the district-targeting accuracy comes out as 0% across the board. We are flagging this loudly because it is a measurement artifact, not an AI failure:
- The Apify Google Maps seed labels every studio with
city = "Berlin"and has no neighborhood field. So a returned studio can never string-match a Bezirk target. - Berlin postcodes do not map 1:1 to Bezirke either (unlike Paris arrondissements, where the postal code is the arrondissement).
- The Paris geography section worked precisely because that 1:1 mapping exists. Without it, the test is null at the data layer.
Do not read this as “AI gets Berlin districts wrong.” The AI engines may or may not be good at this; we simply cannot tell with this seed. A future run with a geocoded-to-Bezirk registry would actually measure it.
Study design
Data collection
- 27 prompt templates × 2 languages (EN/DE) × 2 proxy countries (US/DE) × 5 AI engines
- Engines: ChatGPT, Perplexity, Gemini, Copilot, Google AI Mode (via Bright Data)
- Captured 2026-05-26 → 2026-05-27; ChatGPT model as returned by the engine
- 540 captures · 5,293 citations · 1,110 map entities — all 5 platforms returned on both US and DE proxies (AI Mode × DE worked, unlike the Paris AI-Mode × FR failure)
- For each answer we logged both the rendered text and every cited URL
What we measured
- Studios named per answer (chain-aggregated leaderboard + per-engine split)
- Cited URLs, bucketed into a 7-bucket source taxonomy
- Booking-platform citation share per engine
- EN/DE and US/DE overlap; .de vs .com vs .berlin vs .yoga citation balance
- Comparison of every metric against the Paris May 2026 baseline
How we turned answers into studios: the NER pipeline
AI answers are free text — “You could try Yogicescape in Mitte, or SHA-LA Studios in Prenzlauer Berg…” — not a clean list of businesses. To count anything, we first had to extract the studio mentions. We ran each answer (and each citation’s anchor text) through a named-entity-recognition (NER) pass that works in four steps:
- Span detection. A transformer NER model tags candidate spans in the text — organisation/business names and the location phrases attached to them (Bezirk names, street addresses, postal codes). Yoga-specific gazetteer terms (“Ashtanga,” “Mysore,” “Shala,” “Studio,” “Yoga”) boost recall on names the base model would otherwise miss.
- Normalisation. Each candidate is lower-cased and stripped of boilerplate — the word “Berlin,” Bezirk suffixes (“Mitte,” “Prenzlauer Berg”), trademark glyphs and punctuation — so “yogafürdich Berlin Mitte – Yoga, Pilates & Mediation” and “yogafürdich” collapse toward the same key.
- Entity resolution. Normalised mentions are matched to a canonical studio registry of 631 verified Berlin studios using fuzzy string similarity plus a domain match when the answer cited the studio’s own website. The registry was derived from a 683-row Apify Google Maps seed after filtering out instructors, retreats and pure gyms. A mention only counts if it resolves above a confidence threshold; ambiguous or sub-threshold spans are dropped rather than guessed.
- Chain aggregation. Resolved entities that belong to the same brand (Jivamukti, Three Boons, YOU GLOW…) are merged so a multi-location studio is not double-counted, while per-location coordinates are retained for the maps.
The registry of 631 studios is the universe an answer can resolve to; it is not a list we fed to the models. Everything in the leaderboard is a studio an engine surfaced on its own and that the NER pipeline could confidently identify.
Caveats
- District-accuracy is a null test. The Apify seed has no neighborhood field, so Bezirk-level targeting cannot be measured with this dataset. See Section 7.
- NER resolution is high-precision by design: a mention the pipeline cannot confidently map to the registry is dropped, so counts are conservative lower bounds rather than exhaustive.
- Citation counts pool both in-text overlay citations and the search candidate set; the leaderboards use raw appearances.
- The source taxonomy is approximate — a small share of cites remain in “other” (long-tail Berlin wellness/travel blogs not yet bucketed).
- Google AI Mode’s heavy reliance on google.com URLs may inflate its citation count relative to other engines.
- No personal affiliation: the author has no commercial or training relationship with any Berlin studio in the dataset. (For the equivalent disclosure in the Paris study, see that article.)