AI Search for Bike Shops in Amsterdam (2026):When local businesses actually own the web
TL;DR: Amsterdam bike shops are the cleanest entity-consensus case in the series. Unlike Marseille coffee, where the engines lean on Reddit, Instagram and local blogs, Amsterdam bike-shop answers mostly resolve to the shops’ own websites. Copilot behaves like a phone-book engine: 97% of its citations go to shop domains. Gemini and Perplexity cite shop websites heavily too, at 72% and 71%. ChatGPT is the exception — Reddit is its backbone, the most-cited external domain in the study at 198 citations. Google AI Mode cites google.com back to itself 82% of the time. The result is unusually stable: 12 bike-shop brands appear across all five engines. (27 prompt templates × EN/NL × 2 proxies × 5 engines; 378 captures, against 372 verified shops, 228 with websites.)
Executive Summary
The three citation strategies from the Paris yoga study survive the switch to Amsterdam bike shops intact — but here the engines cite shops’ own sites more, and the top tier wins everywhere. This is the anti-Marseille: where a café scene runs on social and local guides, a bike-shop scene runs on owned, canonical domains.
The setup is deliberately identical to the yoga study: one fixed set of prompts, five engines, two languages, two proxy countries, all in a single week — except this time the question was where to buy or fix a bike in Amsterdam. The full matrix is 540 runs (27 templates × 2 languages × 2 proxies × 5 engines); we retained 378 captures and 3,010 citations after dropped runs (ChatGPT ran the full 108; thinner engine×language×proxy cells lost runs to blocked or empty responses). Shops each answer named were pulled out with a named-entity-recognition pass and matched to a 372-row Apify Google Maps seed (228 of them with a website).
The headline result of the yoga study generalises — but it generalises sharper. Copilot is the pure entity engine at 97% shop-website citations (a phone-book engine); Gemini (72%) and Perplexity (71%) are entity-heavy too — all higher than their yoga equivalents. Gemini is the surprise: in other verticals it often finds one editorial vein, but here the owned-site layer is strong enough that it behaves like an entity engine. ChatGPT learns Amsterdam cycling from Reddit (34% social, with reddit.com alone contributing 198 citations — the most-cited external domain in the study). And Google AI Mode cites google.com 82% of the time, the highest self-referential share measured in this series. The Paris-yoga “Modo problem” — where a top-ranked studio vanished from two engines, showing cross-engine visibility could be brittle — does not recur here: Amsterdam’s top tier wins on every engine.
Three source strategies, sharper than yoga
For every cited URL we bucketed the source — the shop’s own website, social posts, editorial, a marketplace, a Google SERP, or other. The mix is wildly different per engine, and maps to the same three citation strategies we found in Paris yoga — only here, the entity engines are even more entity-heavy.
Entity engine
Copilot, Gemini, Perplexity. Cite the shop’s own website directly. Copilot is the extreme — 97% pure shop-domain citations. Gemini and Perplexity sit just behind at 72% and 71%. To win these engines, your own site has to be the canonical answer for your shop name.
Social engine
ChatGPT. 34% of cited URLs are social — overwhelmingly Reddit. Across the four platforms that cite it, reddit.com contributes 198 citations, making it the most-cited external domain in the entire study. ChatGPT learns Amsterdam cycling from r/Amsterdam threads, not trade press.
Self-referential engine
Google AI Mode. 82% of its citations are google.com URLs — the highest self-referential share in the study, higher even than Paris yoga’s 52%. Real source diversity is minimal; the answer is essentially a re-presented Google SERP.
The Amsterdam bike-shop AI leaderboard
Aggregating each shop’s resolved citations across all five engines (chain locations merged), these are the most-cited Amsterdam bike shops. Score is that cross-engine citation total — resolved citations pointing to the shop’s own domain and pages, summed across the five engines; it is not a raw mention count. Engines is how many of the five surfaced the shop at all — the breadth signal.
The bike shops AI recommends most for Amsterdam — scored across ChatGPT, Perplexity, Gemini, Copilot and Google AI Mode combined.
| Rank | Shop | Score | Engines |
|---|---|---|---|
| #1 | Ride Out Amsterdam | 86 | 5 / 5 |
| #2 | Het Zwarte Fietsenplan | 82 | 5 / 5 |
| #3 | Wheelrunner | 70 | 5 / 5 |
| #4 | Kaptein Tweewielers | 69 | 5 / 5 |
| #5 | 020 Amsterdam Bicycles | 63 | 4 / 5 |
| #6 | Amsterdamse Fietswinkel | 54 | 5 / 5 |
Top cited sources, cross-platform
Aggregating across engines, two patterns emerge. Reddit is the volume outlier — 198 citations, the most-cited external domain in the whole study — but it’s a single domain. The shop sites dominate the breadth ranking: 11 shop domains were cited by all 5 engines.
| Engines | Cites | Bucket | Domain |
|---|---|---|---|
| 5 / 5 | 71 | shop website | hetzwartefietsenplan.com |
| 5 / 5 | 60 | shop website | rideout.amsterdam |
| 5 / 5 | 55 | shop website | wheelrunner.cc |
| 5 / 5 | 45 | shop website | kaptein.cc |
| 5 / 5 | 35 | shop website | amsterdamsefietswinkel.nl |
| 4 / 5 | 198 | social | reddit.com |
The five engines, side by side
Copilot
97% shop websitesThe extreme entity engine. Almost every URL is a shop’s own .nl/.cc/.com domain. No Reddit, no editorial, no marketplace. Win Copilot by being the canonical entity for your shop name.
Perplexity
71% shop websitesHeavy entity bias too, with the most diverse long tail (~23% other). Lightly normalises the prompt into one fan-out search and preserves the prompt language.
Gemini
72% shop websitesLooks like Perplexity on paper — 72% entity-website — but cites fewer URLs and concentrates them on a small set of shop sites.
ChatGPT
34% social (Reddit-led)The social engine. 34% of cited URLs are social, overwhelmingly Reddit — r/Amsterdam threads are how ChatGPT learns Amsterdam cycling.
Google AI Mode
82% google.comThe highest self-referential share in the entire study — even higher than Paris yoga’s 52%. The answer is mostly its own SERP, re-presented.
Language & the search mechanism
Asking the same question in Dutch vs English does not just rerank the same shops — it returns a different shop set entirely for generic and use-case queries. Brand and tourist queries converge; everything else diverges. The mechanism is visible in Perplexity’s exposed search query.
| Template | Top-5 overlap (EN vs NL) |
|---|---|
| brand_brompton | 75% — highest |
| persona_tourist | 67% |
| service_fitting | 67% |
| type_vintage | 50% |
| dist_jordaan | 43% |
| dist_oost | 43% |
Brand and tourist queries have a single right answer regardless of language. But a Dutch fietsenmaker (repair), stadsfiets (Dutch city bike) or commuter query returns an almost entirely different shop set than its English equivalent — 0% top-5 overlap on four of the templates. What’s going on?
fanout_count = 1: Perplexity does not expand a prompt into multiple sub-searches the way ChatGPT’s fan-out does. It lightly normalises the prompt — drops filler (“in”), pluralises, reorders — into a single search string, and crucially preserves the prompt language.| Original prompt | Perplexity’s actual search |
|---|---|
| beste traditionele Hollandse fietsenwinkel in Amsterdam | beste traditionele Hollandse fietsenwinkels Amsterdam |
| beste kinderfiets winkels in Amsterdam | beste kinderfiets winkels Amsterdam |
| beste fietsenwinkels voor woon-werkverkeer in Amsterdam | beste fietsenwinkels woon-werkverkeer Amsterdam |
TLD bias: Dutch changes the shops, not the domains
If language drives such a big EN/NL divergence in which shops appear, does it also drive which TLDs are cited? No.
| TLD | Entities | EN cites | NL cites | EN / NL ratio | Reading |
|---|---|---|---|---|---|
| .nl | 31 | 43 | 42 | 0.98× | neutral |
| .com | 6 | 15 | 12 | 0.80× | neutral |
| .cc | 3 | 7 | 5 | 0.71× | EN-biased |
| .amsterdam | 3 | 5 | 5 | 1.00× | neutral |
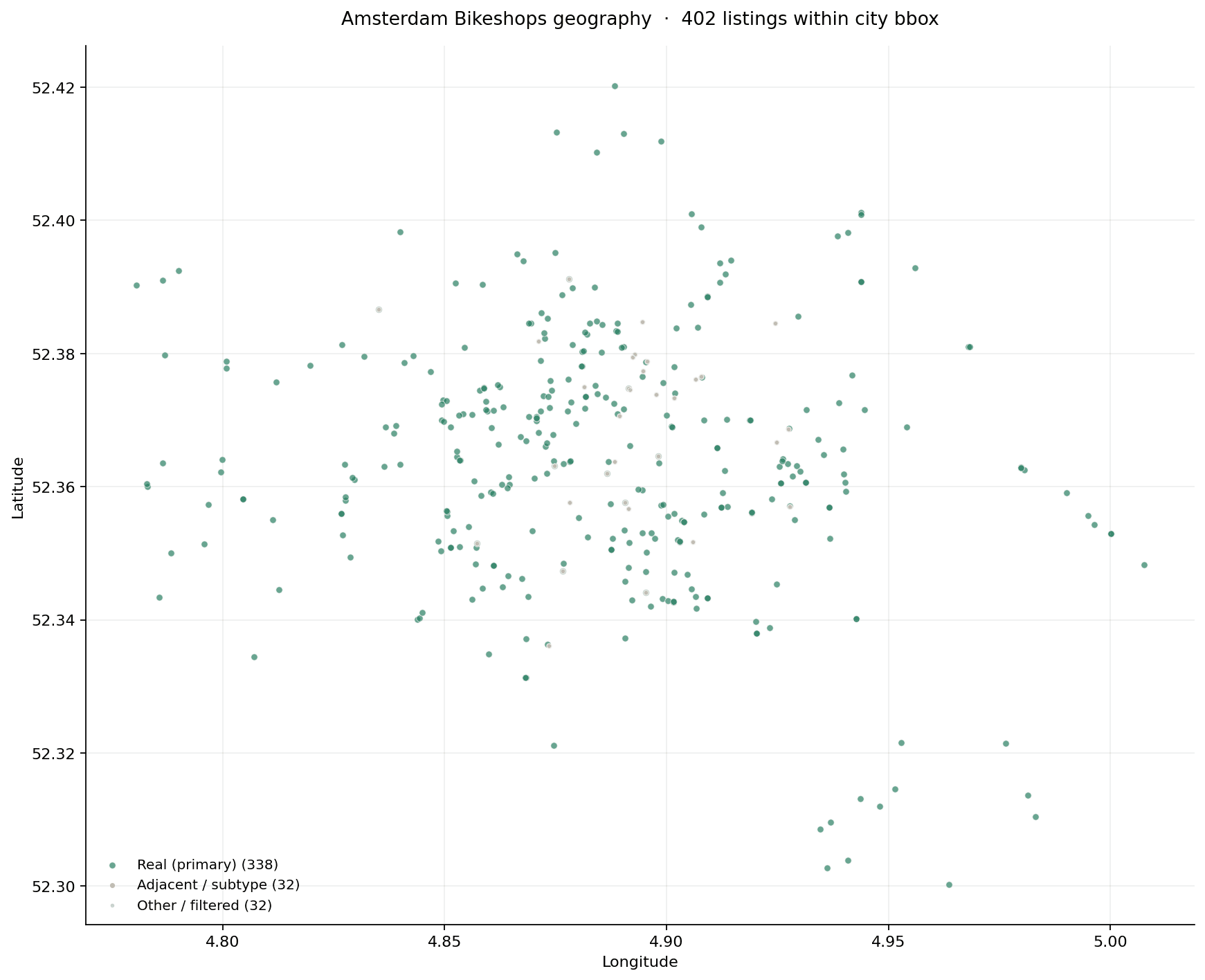
Geography
The 372-row seed plotted geographically. Density follows the canal belt and Oost; sparse in Noord and the outer rings. These maps are the universe an AI answer can resolve to.
AI search behavior
How do the engines actually fetch their answers? Two windows into the mechanism — ChatGPT’s web-search trigger and Perplexity’s exposed fan-out — show how much grounding is happening behind every answer.
Even more search-dependent than Paris yoga (96%). Not one bike-shop prompt was answered from training memory alone.
Perplexity does not multi-search a single prompt. It lightly normalises and runs one search, in the prompt’s language.
The prompt library
Everything in this article rests on the prompt set. 27 templates, each written once in English and once in Dutch, fired from both a US and an NL proxy on all 5 engines. The matrix probes the dimensions that matter for local discovery: bike type, persona, price, service, brand, district — plus two deliberate entity-bleed controls (scooter, general sports) to measure how cleanly the models separate adjacent verticals.
control | ENbest bike shops in Amsterdam | NLbeste fietsenwinkels in Amsterdam |
type_dutch | ENbest Dutch city bike shops in Amsterdam | NLbeste stadsfietsen winkels in Amsterdam |
type_ebike | ENbest e-bike shops in Amsterdam | NLbeste e-bike winkels in Amsterdam |
type_road | ENbest road bike shops in Amsterdam | NLbeste racefiets winkels in Amsterdam |
type_mtb | ENbest mountain bike shops in Amsterdam | NLbeste mountainbike winkels in Amsterdam |
type_gravel | ENbest gravel bike shops in Amsterdam | NLbeste gravelbike winkels in Amsterdam |
type_cargo | ENbest cargo bike shops in Amsterdam | NLbeste bakfiets winkels in Amsterdam |
type_kids | ENbest kids bike shops in Amsterdam | NLbeste kinderfiets winkels in Amsterdam |
type_vintage | ENbest vintage bike shops in Amsterdam | NLbeste vintage fietsen winkels in Amsterdam |
persona_commuter | ENbest bike shops for commuters in Amsterdam | NLbeste fietsenwinkels voor woon-werkverkeer in Amsterdam |
persona_tourist | ENbest bike shops for tourists in Amsterdam | NLbeste fietsenwinkels voor toeristen in Amsterdam |
price_cheap | ENcheap bike shops in Amsterdam | NLgoedkope fietsenwinkels in Amsterdam |
price_premium | ENpremium bike shops in Amsterdam | NLhigh-end fietsenwinkels in Amsterdam |
service_repair | ENbest bike repair shops in Amsterdam | NLbeste fietsenmakers in Amsterdam |
service_fitting | ENbest bike fitting in Amsterdam | NLbeste bikefitting in Amsterdam |
service_custom | ENcustom bike builders in Amsterdam | NLfietsenbouwers op maat in Amsterdam |
brand_brompton | ENBrompton dealer Amsterdam | NLBrompton dealer Amsterdam |
brand_specialized | ENSpecialized dealer Amsterdam | NLSpecialized dealer Amsterdam |
dist_centrum | ENbest bike shops in Centrum Amsterdam | NLbeste fietsenwinkels in Centrum Amsterdam |
dist_pijp | ENbest bike shops in De Pijp Amsterdam | NLbeste fietsenwinkels in De Pijp Amsterdam |
dist_jordaan | ENbest bike shops in Jordaan Amsterdam | NLbeste fietsenwinkels in Jordaan Amsterdam |
dist_noord | ENbest bike shops in Noord Amsterdam | NLbeste fietsenwinkels in Noord Amsterdam |
dist_oost | ENbest bike shops in Oost Amsterdam | NLbeste fietsenwinkels in Oost Amsterdam |
secondhand | ENbest second hand bike shops in Amsterdam | NLbeste tweedehands fietsenwinkels in Amsterdam |
independent | ENbest independent bike shops in Amsterdam | NLbeste onafhankelijke fietsenwinkels in Amsterdam |
bleed_scooter | ENbest scooter shops in Amsterdam | NLbeste scooterwinkels in Amsterdam |
bleed_generalist | ENbest sports shops in Amsterdam | NLbeste sportwinkels in Amsterdam |
Study design
Data collection
- 27 prompt templates × 2 languages (EN/NL) × 2 proxy countries (US/NL) × 5 AI engines
- Engines: ChatGPT, Perplexity, Gemini, Copilot, Google AI Mode
- 378 captures, 3,010 citations, captured 2026-05-23 → 2026-05-24
- For each answer we logged both the rendered text and every cited URL
What we measured
- Shops named per answer (brand-aggregated leaderboard + per-engine breadth)
- Cited URLs, bucketed into a source taxonomy
- EN/NL top-5 overlap per template (Jaccard)
- .nl vs .com vs .cc citation balance by prompt language
- ChatGPT web-search trigger rate; Perplexity fan-out search query
How we turned answers into shops: the NER pipeline
AI answers are free text — “You could try Wheelrunner in De Pijp, or Het Zwarte Fietsenplan for second-hand bikes…” — not a clean list of businesses. To count anything, we ran each answer (and each citation’s anchor text) through a named-entity-recognition (NER) pass that works in four steps:
- Span detection. A transformer NER model tags candidate spans in the text — organisation/business names and the location phrases attached to them (district names, street addresses). Cycling-specific gazetteer terms (“fietsenwinkel,” “tweewielers,” “bakfiets,” “cycles”) boost recall on names the base model would otherwise miss.
- Normalisation. Each candidate is lower-cased and stripped of boilerplate — “Amsterdam,” district suffixes, trademark glyphs and punctuation — so “Het Zwarte Fietsenplan B.V.” and “Het Zwarte Fietsenplan” collapse toward the same key.
- Entity resolution. Normalised mentions are matched to a 372-row Apify Google Maps seed (228 with websites) using fuzzy string similarity plus a domain match when the answer cited the shop’s own website. A mention only counts if it resolves above a confidence threshold; ambiguous spans are dropped rather than guessed.
- Brand aggregation. Resolved entities that belong to the same brand are merged so a multi-location shop is not double-counted, while per-location coordinates are retained for the maps.
The 372-shop seed is the resolution universe a named shop can match; the 228 with websites are the subset eligible for domain-based citation matching. The seed is not a list fed to the models. Everything in the leaderboard is a shop an engine surfaced on its own and that the NER pipeline could confidently identify.
Caveats
- The seed is the 372-row Apify Google Maps pull of Amsterdam bicycle shops, repair shops and used / e-bike specialists. Rental services, tour operators and pure e-commerce stores are filtered out (
is_real = false). 228 of the 372 have a website and so are eligible for domain-based citation resolution. - NER resolution is high-precision by design: a mention the pipeline cannot confidently map to the seed is dropped, so counts are conservative lower bounds rather than exhaustive.
- The district-targeting test (Centrum, De Pijp, Jordaan, Noord, Oost) returned 0% across all neighborhoods. This is a measurement artifact, not an AI failure: the seed has no neighborhood-level field, so a returned shop cannot match a Jordaan/Centrum target by construction. The test is null for Amsterdam.
- Only ChatGPT exposes a web-search trigger flag through the capture pipeline; only Perplexity exposes its internal search query. The other engines’ behaviour is unmeasured, not absent.
- Google AI Mode’s 82% self-citation may inflate its raw citation count relative to other engines.
- Grok is excluded from this study; the crawler returned a wait-element timeout for the bike-shop prompt set.
The clean control case
Amsterdam is the cleanest entity-consensus case in the series because the local web gives the engines something clean to agree on. Bike shops here have stronger owned domains than the yoga studios, cafés and bookstores in the other studies — so Copilot turns that into near-pure shop-website citation, and Gemini and Perplexity follow the same direction. The top shops aren’t platform-specific accidents: twelve brands appear across all five engines.
But the consensus has one exception: ChatGPT still learns Amsterdam cycling through Reddit. So even in the cleanest owned-web case, the playbook isn’t “website only.” It’s canonical website first, social proof second.
The language result adds the final wrinkle. Dutch prompts don’t simply rerank the English answer — they return different shop sets. The domains stay similar; the entities change.
Set against Marseille coffee, the pair sketches a small taxonomy of local internet ecosystems — AI visibility tracks the shape of the local web. Marseille coffee runs on Instagram and local blogs; Amsterdam bikes run on owned, canonical domains. Part of the reason is structural: a bike shop sells and services bikes on its site, so the website does real work and gets built, linked and crawled; a café has no such transaction. In Marseille, AI search smelled like Instagram and local blogs. In Amsterdam, it looks more like a well-indexed shopfront. Less romantic — much easier to optimise.